
An introduction into the concepts of disaster recovery and a walkthrough of Azure site recovery options.
In my opinion, one of the primary infrastructure related services that Azure provides is Azure site recovery. In this day and age, when service downtime results in substantial financial losses, IT organizations have had to adopt comprehensive business continuity and disaster recovery (BCDR) plans.
A comprehensive BCDR strategy requires you utilize site recovery and back up features. To understand why we must have an understanding of Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
Recovery point objectives (RPO) is the point in time to which you can recover your data.
Backup policies determine the RPO for a backup solution. With a daily backup policy, the RPO is closer to a day. Few factors affect the RPO for replication. Azure Site Recovery provides continuous replication for Azure VMs, VMware VMs, and Hyper- V VMs. For Hyper-V VMs, replication frequency can be as low as 30 seconds.
Recovery time objective (RTO) is the time it takes to fully recover your services.
When designing and planning for a low RTO, it is important to understand the variables that are not always under your control. For instance, if a restore is initiated, the time it takes to have the services back up and running is determined by variables like the size of the restore, available network bandwidth, and the speed of the disk drives/VMs, etc.
The RTO for a backup solution is dependant on the size of the data and the infrastructure you would have had to have configured first. Azure site recovery has few extra dependencies including how long it takes to provision the DR infrastructure on the ‘other side’, the speed of the disk drives/VMs, time to run the recovery plan, time to propagate the appropriate DNS changes to point to the ‘other’ side, etc. Generally in the ~minutes to many minutes range.
According to the SLA for Azure site recovery “Monthly Recovery Time Objective” ” for a specific Protected Instance configured for On-Premises-to-Azure replication in a given billing month is four hours for an unencrypted Protected Instance and six hours for an encrypted Protected Instance. One hour will be added to the monthly Recovery Time Objective for each additional 25GB over the initial 100GB Protected Instance size”.
Why should you still utilize back up services with site recovery? Back up service provides individual back up for drives and VMs. You are more likely to use back up services more frequently than your site recovery service. In no way can one be substituted for another in regards to protecting your services and data.
Azure Site Recovery Options.
If you are already managing a data center, you would have a BCDR strategy that utilizes a secondary data center. The options you have with Azure site recovery are:
- To have a highly available service orchestrate and manage the disaster recovery strategy.
- Have Azure site recovery replicate the data and spin up the resources in Azure and have Azure be your secondary recovery site.
Outside of these primary uses Azure site recovery also provides two other functions.
- Replicate Azure resources via site recovery to failover to another region in case of disasters or downtime in one region.
- Migrate workloads on to Azure from on-premises or AWS.
Microsoft provided extensive documentation on the configuration of each of these aspects. I hope to provide an overview with links for deep dives on each scenario. I hope to in a later article to primarily focus on Azure protection and failover to a different region within Azure, since it was a recently made available. (Note: You could set up Azure to Azure site recovery in the same region before)
1. Replication to a secondary site
A. VMware and physical servers.
B. Hyper-V Vms and physical VMs.
A. VMware and physical servers.
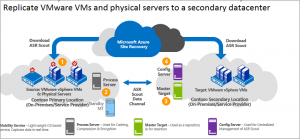
1. InMage Scout is downloaded when you pick your objective in Azure site recovery console.
The component servers are required at each site.
Secondary site.
4. Configuration server – manages, configure, and monitor your deployment, either using the management website or the vContinuum console.
3. Master Target – holds replicated data. It receives data from the process server (ASR Scout Data Channel), creates the replica machines in the secondary site, and holds the data retention
Primary site
2. Process Server – handles caching, compression, and data optimization
B. Hyper-V Vms and physical VMs.
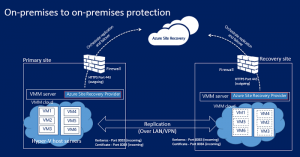
For data centers utilizing Hyper-V, Microsoft Virtual Machine Manager (VMM) is utilized on both the primary and secondary sites.
Data is replicated between the primary and secondary Hyper-V host servers over the LAN or VPN connection, using Kerberos or certificate authentication.
2. Replication to Azure.
A. VMware and physical servers.
B. Hyper-V Vms and physical VMs.
A. VMware and physical servers.
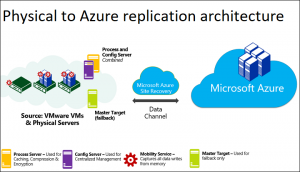
Replicated data from on-premises VMs is stored in the storage account. Azure VMs are created with the replicated data when you run a failover from on-premises to Azure. The Azure VMs connect to the Azure virtual network when they’re created.
During Site Recovery deployment, you add VMware servers to the Recovery Services vault for access to VMware Virtual Machines.
B. Hyper-V Vms and physical VMs.
The process changes based on whether your data center uses system center virtual machine manager (VMM) vs if you don’t use virtual machine manager (VMM).
- Replicated data from on-premises VM workloads is stored in the Azure storage account.
- You install the Azure Site Recovery Provider and Recovery Services agent on each standalone Hyper-V host, or on each Hyper-V cluster node.
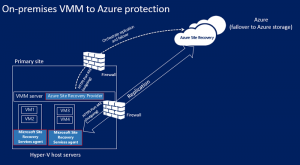
With sites that have Virtual Machine Manager (VMM), You install the Site Recovery Provider on the VMM server, to orchestrate replication with Site Recovery, and register the server in the Recovery Services vault.
You will still need to install the Recovery Services agent on each Hyper-V host or cluster nodes.
Configuring Azure site recovery for your BCDR strategy does require some effort. You must thoroughly examine the SLA, requirements, and parameters before settling on utilizing a cloud service as a part of your BCDR strategy. Once you have decided to use a cloud service and configured it, you should thoroughly test the resiliency of your service and configuration with failover and failback testing.
Outside of Azure, there are several services that provide BCDR services in the cloud, referred to as DRaaS (Disaster Recovery as a Service). Additionally, you have standards in BCDR that continue to be an emerging trend, with many developed in recent years from organizations such as the International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC).
Furthermore, separate from the technology that supports the BCDR strategy should be procedures and supporting documentation that directly guides the shifting of services in disaster recovery scenarios. It should be a seamless process that has already been thought out, planned for and can be executed by more than a few of your system admins.
(Banner Credit:Nines Observer Comic no. 9 Disaster Recovery)